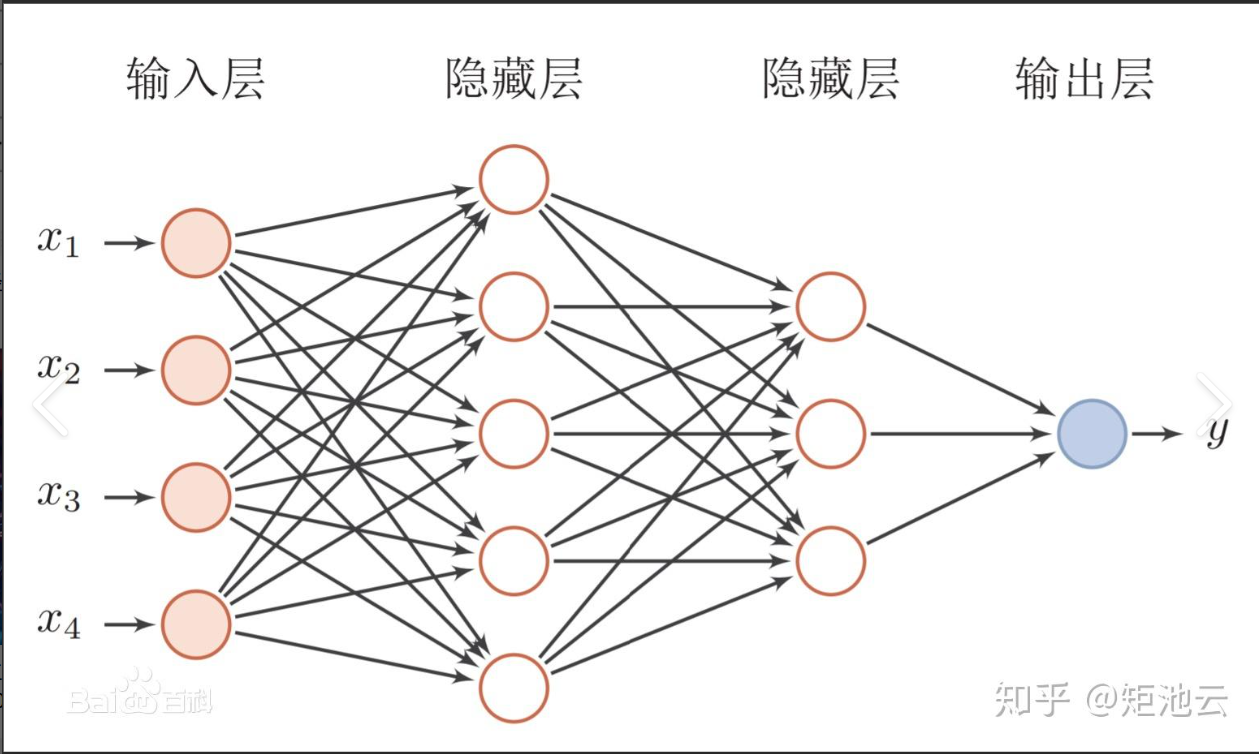
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
import torch
import numpy as np
import random
import torchvision
input_size = 784
num_classes = 10
batch_size = 256
num_epochs = 20
lr = 0.1
# W = torch.randn((input_size, num_classes), requires_grad=True)
#只能生成高斯分布均值为0,方差为1的随机数,不能指定均值和方差
W= torch.normal(0, 0.01, size=(input_size, num_classes), requires_grad=True)
b = torch.zeros((num_classes,), requires_grad=True)
trans = torchvision.transforms.ToTensor()
# 1.转化为tensor 2.归一化到[0,1] 3.形状变为channel*H*W
mnist_train = torchvision.datasets.FashionMNIST(root='data', train=True, download=True, transform=trans)
train_loader = torch.utils.data.DataLoader(mnist_train, batch_size, shuffle=True)
mnist_test = torchvision.datasets.FashionMNIST(root='data', train=False, download=True, transform=trans)
test_loader = torch.utils.data.DataLoader(mnist_test, batch_size, shuffle=False)
def softmax(X):
'''
softmax 的 Docstring
:param X: 二维矩阵,每行代表一个样本,每列代表一个类别,即每行代表一个样本的各类别的得分
'''
X_exp = torch.exp(X)
example_sum = X_exp.sum(dim=1, keepdim=True)
return X_exp / example_sum
def net(X):
'''
net 的 Docstring
batch_size*(H*W) @ (H*W)*num_classes -> batch_size*num_classes
:param X: 输入数据,形状为 (batch_size, 1, 28, 28),需要先 reshape 成 (batch_size, 784) 才能与权重矩阵 W 相乘.
'''
return softmax(torch.matmul(X.reshape(-1,W.shape[0]), W) + b)
# 这里reshape不会改变原始数据形状, 也不创建新副本, 数据还是那个数据,这里创建了一个新视图,改变了查看数据的方式
def cross_entropy(y_hat, y):
return -torch.log(y_hat[range(len(y_hat)), y] + 1e-9)
loss = cross_entropy
for epoch in range(num_epochs):
train_loss, n = 0, 0
for X, y in train_loader:
# print(f"X_shape_init: {X.shape}") # torch.Size([256, 1, 28, 28])
y_hat = net(X)
l = loss(y_hat, y)
# print(f"y shape: {y.shape}") # torch.Size([256])
# print(f"loss shape: {l.shape}") # torch.Size([256])
(l.sum() / X.shape[0]).backward()
train_loss += l.sum().item()
n += X.shape[0]
with torch.no_grad():
lr_real = lr * (0.90 ** epoch)
W -= lr_real*W.grad # -=:原地修改 W = W - lr*W.grad:产生新的W
b -= lr_real*b.grad
W.grad.zero_()
b.grad.zero_()
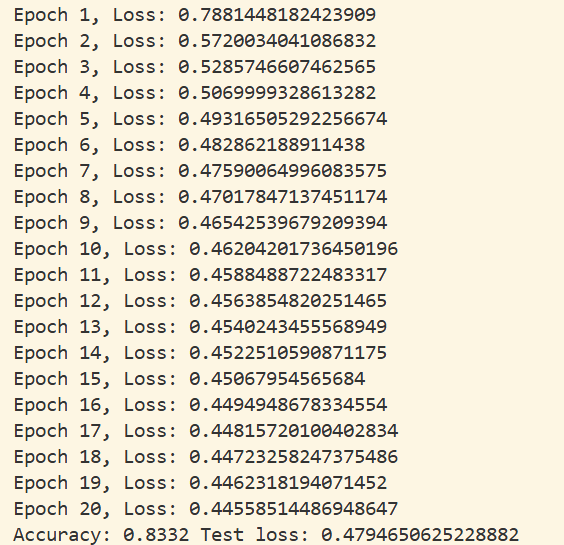
print(f"Epoch {epoch+1}, Loss: {(train_loss / n)}")
correct, total, loss_total = 0, 0, 0
for X, y in test_loader:
y_hat = net(X)
loss_total += loss(y_hat, y).sum().item()
correct += (y_hat.argmax(dim=1).type(y.dtype) == y).sum().item()
# a.type(B):将a转换为B类型 或 a.to(B)
# a.dtype:查看a的数据类型
total += y.shape[0]
print(f"Accuracy: {correct / total} Test loss: {loss_total / total}")
|